Automatizando la vida diaria: Amazon
Estoy convencido de que saber un lenguaje de programación puede ayudarte no solo en tu vida profesional y/o académica sino también en tu vida diaria, por ello he decidido empezar una serie llamada Automatizando la vida diaria, donde mostraré cómo automatizar algunos procesos cotidianos.
En este primer post enseñaré como obtener comentarios de productos de Amazon usando R para aplicarles un poco de analytics y así sacarles provecho a la hora de elegir un producto.
Motivación
Como a muchos, me preocupa que al hacer compras por internet esté eligiendo el producto adecuado dado que no podré verlo sino hasta que me lo entreguen 😬. Por ello cuando estoy en busca de un producto suelo pasar una buena parte de tiempo viendo/leyendo reseñas para asegurarme de hacer una buena elección pero a pesar del esfuerzo nunca podré leerlas todas y hay ocasiones en donde preferiría ocupar mi tiempo en algo más interesante que eso, honestamente sería mucho más fácil si alguien lo hiciera por mi 😆.
Pues de esa necesidad e inspirado por este post se me ocurrío que el proceso de análisis de las opiniones de productos en Amazon bien puede automatizarse usando R.
Requisitos
Para el proceso de descarga de las opiniones usaremos las siguientes librerías.
{rvest}: Este paquete es el que nos permitirá descargar información de páginas web.
{polite}: Con este paquete seremos educados al hacer scrapping para evitar romper ciertas reglas sobre el uso de bots en la navegación web.
{stringr}: Este lo usaremos para el proceso de limpieza.
{purrr}: Este no está directamente relacionado con la tarea de descarga de información pero nos ayudará en las funciones que crearemos.
Y por supuesto usaremos Amazon como el sitio para descargar las opiniones.
Adicionalmente, para análisis las opiniones extraídas usaremos el paquete {udpipe}.
(Muy) Breve introducción a web scrapping
El termino web scrapping hace referencia a una técnica que permite extraer información de sitios web para exportarla a formatos que sean más amigables y/o útiles.
Generalmente esto significa que la información que necesitamos no está disponible en ningún archivo y el único lugar donde se encuentra es justamente la página web.
El proceso de extracción no suele ser sencillo dado que hay una gran cantidad de tipos de sitios web y sus respectivas configuraciones harán que el algoritmo de extracción varíe, sin embargo suele ser más fácil (y rápido) que extraer la información manualmente, i.e. CTRL+C & CTRL+V.
Para poder hacer la extracción será necesario saber dónde está la información. Para simplificar las cosas pensemos que una página web funciona como un directorio de nuestra computadora, así que será necesario entender en qué carpeta está eso que queremos; para encontrarla usaremos las herramientas de desarrollador disponibles en algunos buscadores (en nuestro caso usaremos Google Chrome).
En Chrome será tan fácil cómo colocar el cursor sobre el contenido de interés, dar click derecho y luego dar click en Inspect o Inspeccionar.
Extrayendo comentarios de Amazon
¿Dónde están los comentarios?
Primero será pertienente mencionar que cada producto en Amazon viene con código único que lo identifica y que podemos encontrar en la URL del producto:
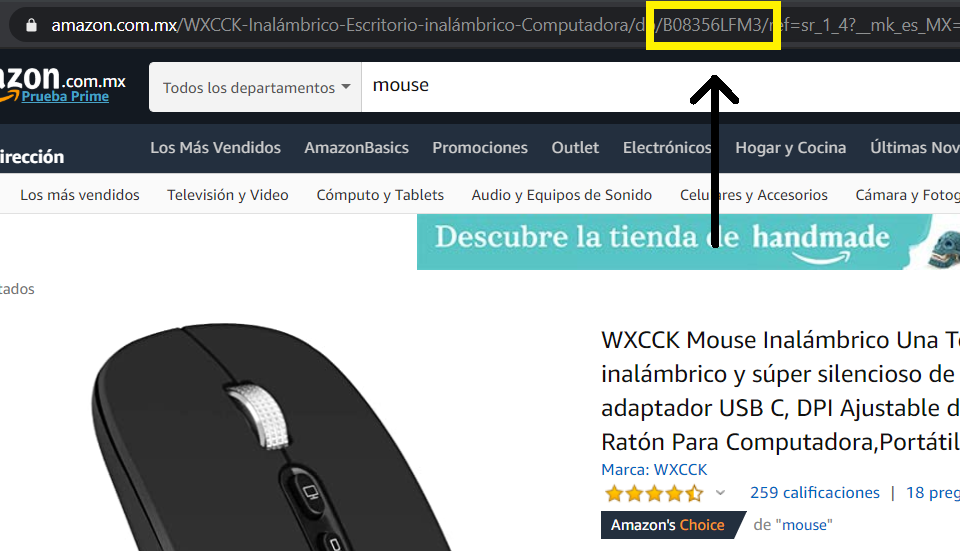
Una vez identificado el código del producto podemos usarlo para buscar la opiniones de éste, si bien podemos encontrarlas en la misma página en la que estemos viendo el producto, será más fácil (para la automatización) usar la dirección: www.amazon.com.mx/product-reviews/“código_del_producto”. En nuestro ejemplo esta dirección se convierte en: www.amazon.com.mx/product-reviews/B08356LFM3.
Ahora sí, usando la herramienta de inspección de Chrome podemo identificar dónde están guardados los comentarios:
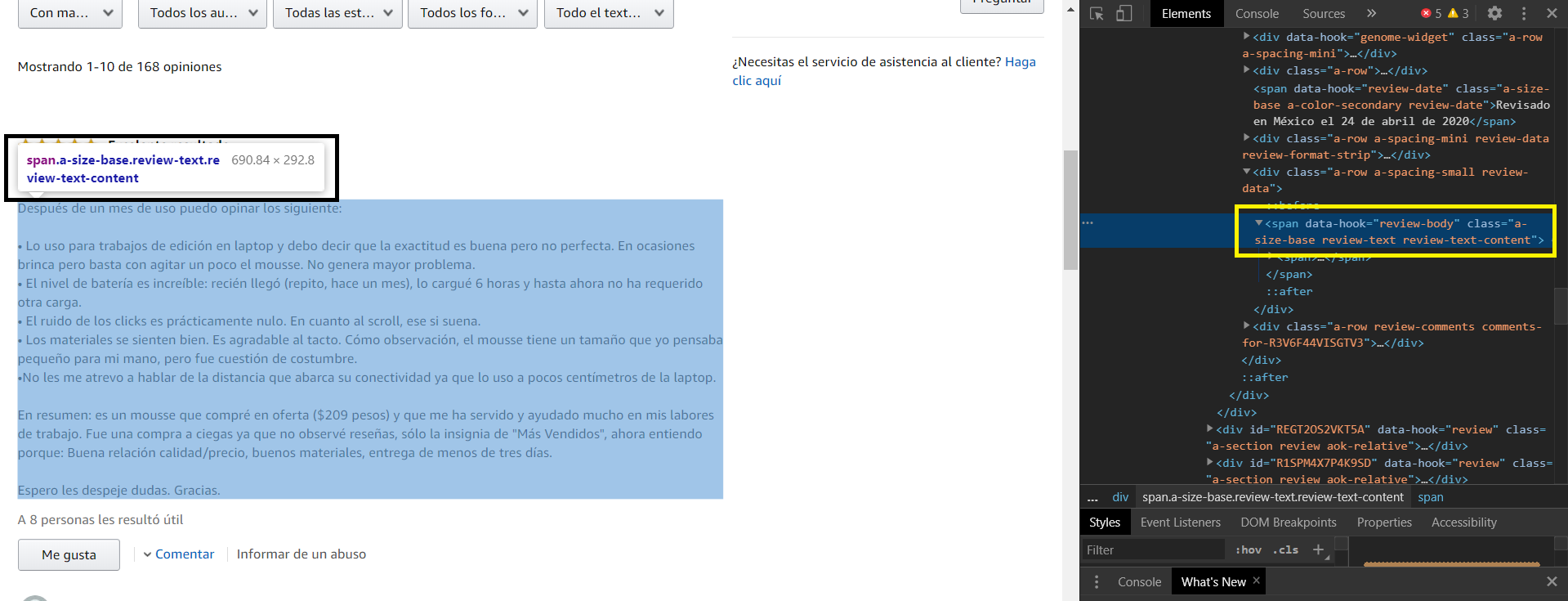
Notemos además que si queremos ver otra página de opiniones la dirección quedaría construída como sigue: https://www.amazon.com.mx/product-reviews/B08356LFM3/?pageNumber=2
Automatizando la extracción
Una vez entendido (más o menos) de dónde obtener la información podemos crear las funciones necesarias para automatizar la extracción.
La primera función será la que justamente hará el trabajo de extracción:
get_reviews <- function(id, pages){
webpage <- paste0("https://www.amazon.com.mx/product-reviews/", id)
session <- bow(webpage)
reviews_list <- map(1:pages, ~scrape(session, query = list(pageNumber = .x)) %>%
html_nodes("[class='a-size-base review-text review-text-content']") %>%
html_text())
reviews <- clean_reviews(unlist(reviews_list))
return(reviews)
}Notemos que adicionalmente estamos usando una función que nos permite limpiar las opiniones extraídas y que está definida como sigue:
clean_reviews <- function(reviews){
cleaned <- str_replace_all(reviews, "[\r\n]", "") %>%
str_replace_all(., "[.]", " ") %>%
str_replace_all(., "[,]", " ") %>%
str_replace_all(., "[;]", " ") %>%
str_replace_all(., "[\"]", " ") %>%
tolower() %>%
trimws() %>%
paste(collapse = " ")
return(cleaned)
}N.B. Esta función de limpieza la cree después de hacer una primera descarga.
Y listo, en realidad esas son las funciones esenciales que necesitamos para extraer los comentarios 😅.
Para extraer comentarios de e.g. este producto correremos lo siguiente:
opiniones <- get_reviews("B01IDNQDSS", 10)El objeto opiniones será un vector de un elemento en el cuál estarán las opiniones de 10 páginas.
Ahora que ya tenemos esto descargado podemos aplicarles un poco de analytics para analizarlos.
Analizando los comentarios
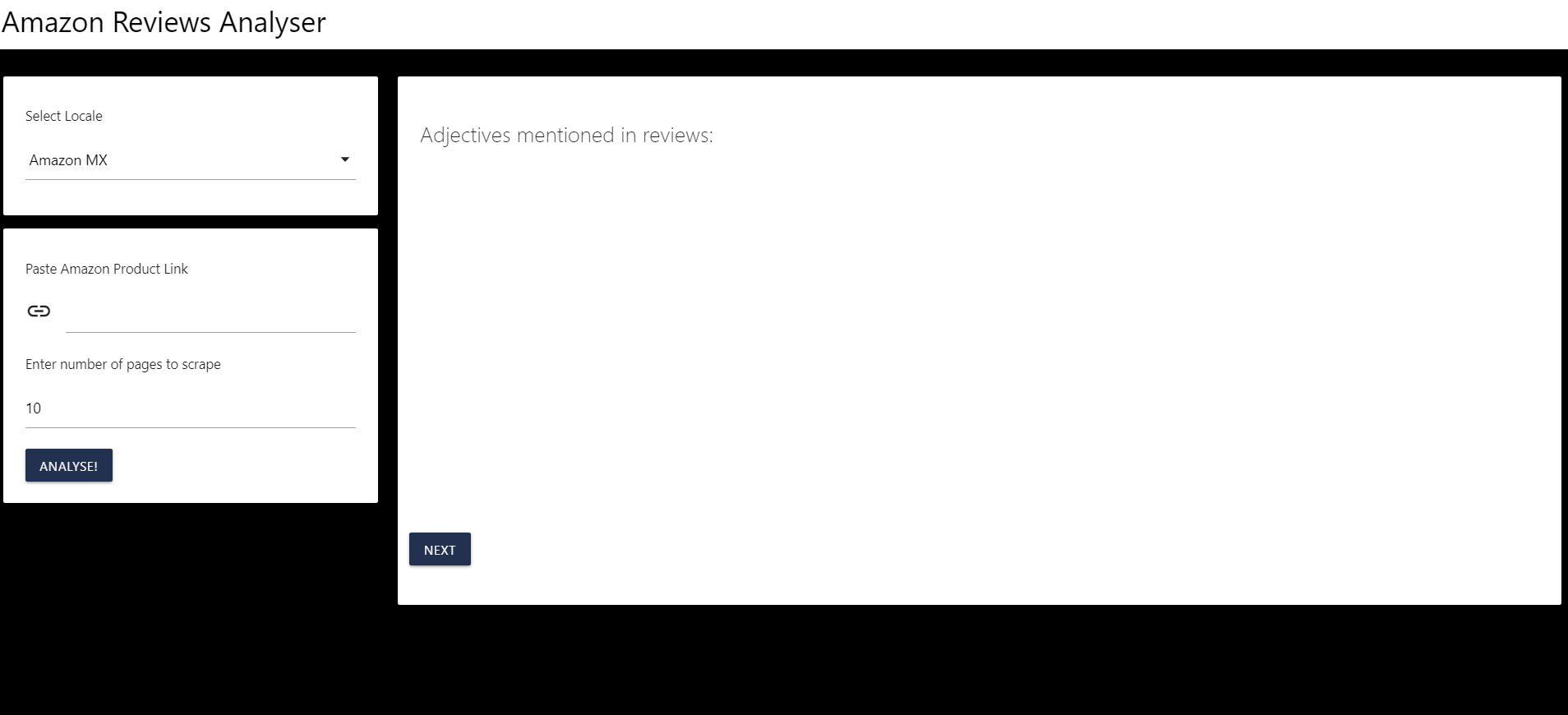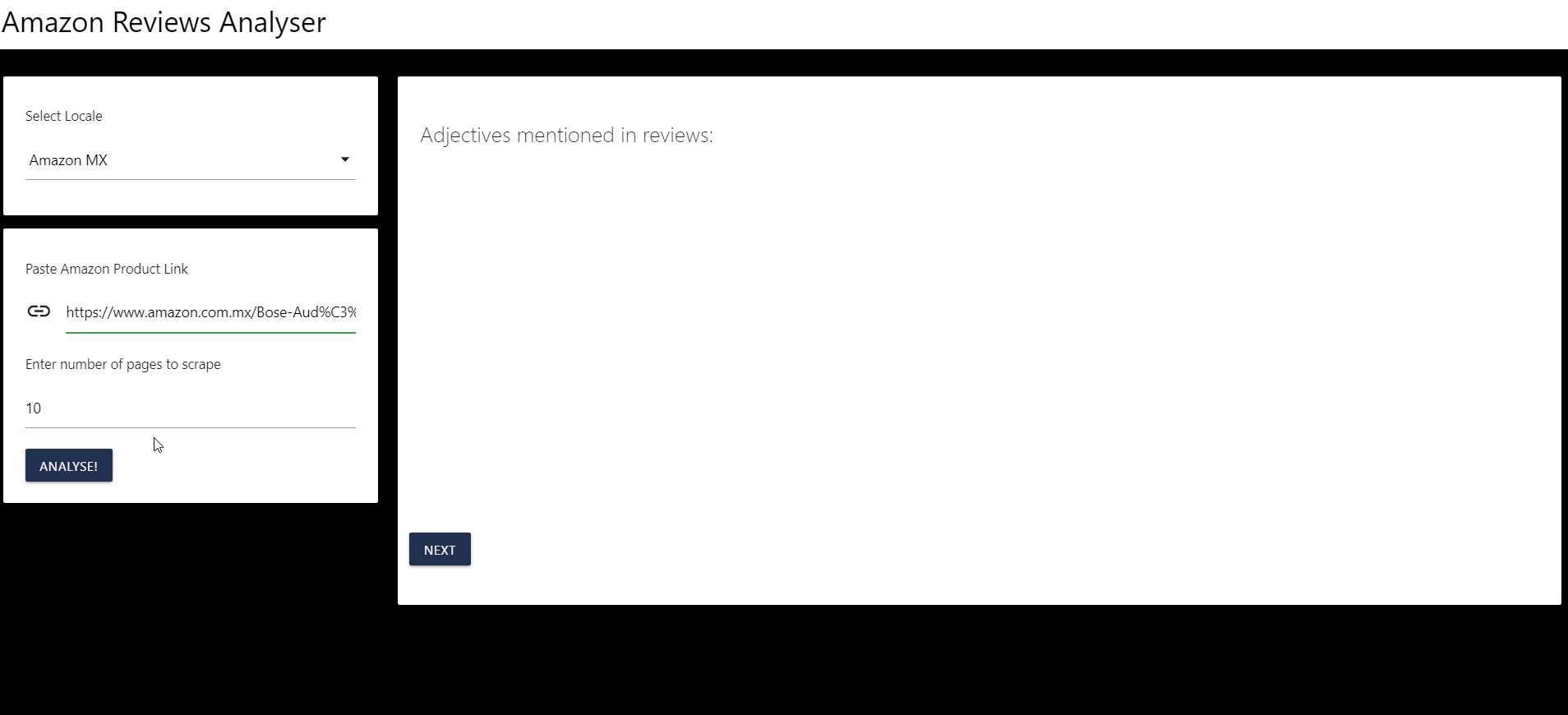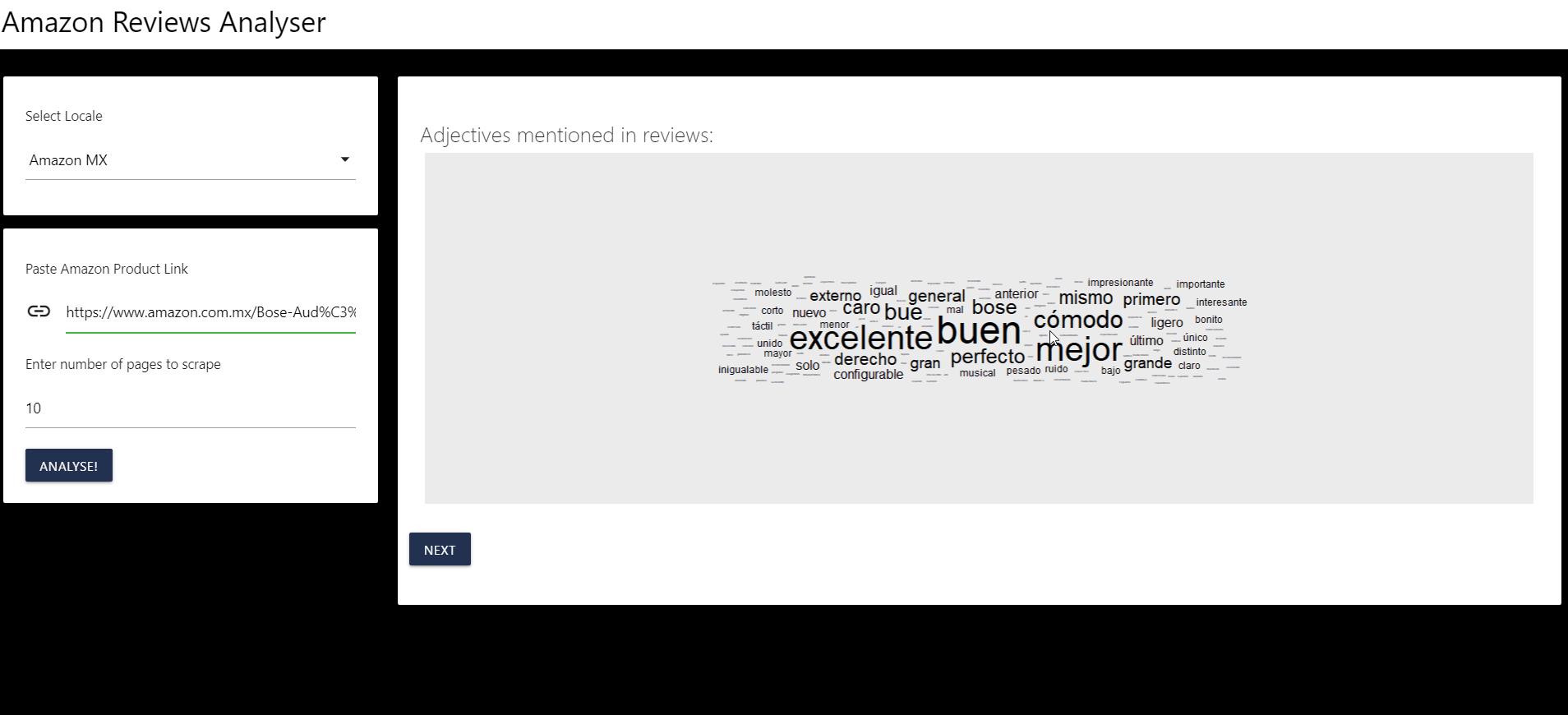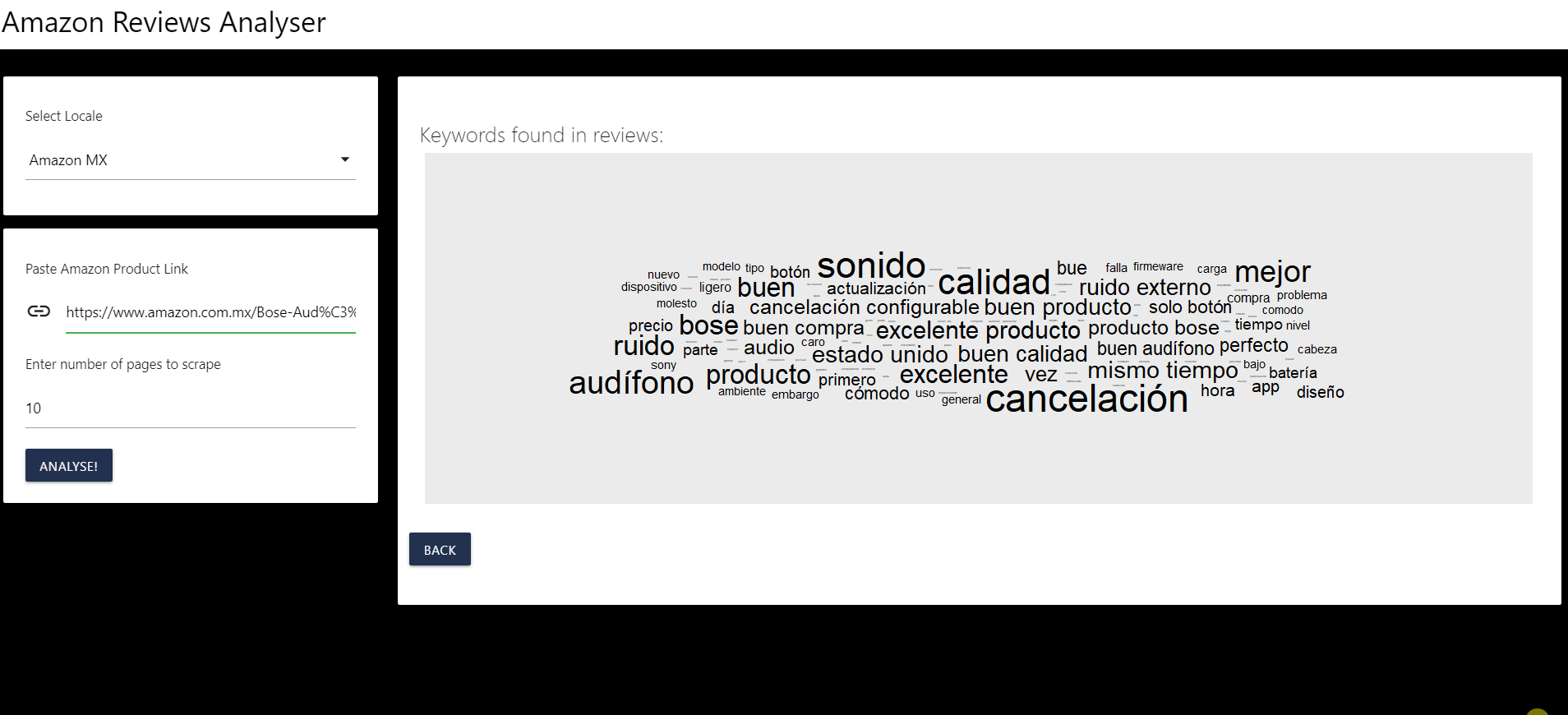
El análisis más sencillo que se puede aplicar es crear nubes de palabras sin embargo éstas no son muy informativas pues solo consisten de frecuencias.
En lugar de ello lo que haremos será:
Identificar los adjetivos com mayor ocurrencia en las opiniones.
Extraer las palabras/frases clave en ellas
Como lo mencionabamos anteriormente, para estas tareas usaremos la librería {udpipe}, la cual nos permitirá aplicar técnicas de procesamiento de lenguaje natural como tokenización y lematización.
Lo primero que haremos será cargar el modelo pre-entrenado para el idioma español:
# udpipe_download_model(language = "spanish-gsd")
model <- udpipe_load_model("spanish-gsd-ud-2.4-190531.udpipe")Ahora, le aplicaremos el modelo a nuestras opiniones:
x <- udpipe_annotate(model, opiniones)
x <- as.data.frame(x, detailed = TRUE)Básicamente lo que esto hace es tomar cada palabra del vector de opiniones y evaluar si ésta es un verbo, adjetivo, adverbio, sustantivo, etc.
También lematiza cada palabra, es decir, encuentra su palabra representante, por ejemplo para las palabras [caminando, caminé, caminaba] su representante o lema será [caminar].
E incluso el modelo identifica características morfológicas de la palabra como el género, las formas personales (en el caso de los verbos) o si se está usando de forma singular o plural.
| token | lemma | upos | xpos | feats | head_token_id | dep_rel | deps | misc |
|---|---|---|---|---|---|---|---|---|
| soy | ser | AUX | NA | Mood=Ind|Number=Sing|Person=1|Tense=Pres|VerbForm=Fin | 2 | cop | NA | NA |
| estudiante | estudiante | NOUN | NA | Number=Sing | 16 | nsubj | NA | NA |
| y | y | CCONJ | NA | NA | 4 | cc | NA | NA |
| paso | paso | NOUN | NA | Gender=Masc|Number=Sing | 2 | conj | NA | NA |
| más | más | ADV | NA | Degree=Cmp | 7 | advmod | NA | NA |
| de | de | ADP | NA | NA | 5 | case | NA | NA |
Con toda esta información podemos explorar fácilmente los adjetivos más frecuentes dentro de las opiniones:
adj_stats <- x %>%
dplyr::filter(upos == "ADJ")
adj_stats <- txt_freq(adj_stats$lemma)
ggplot(head(adj_stats, 20), aes(reorder(key, freq_pct), freq_pct))+
geom_point()+
geom_linerange(aes(ymin = 0, ymax = freq_pct))+
labs(x = "", y = "Frecuencia (%)")+
ggtitle("Adjetivos")+
coord_flip()+
theme_minimal()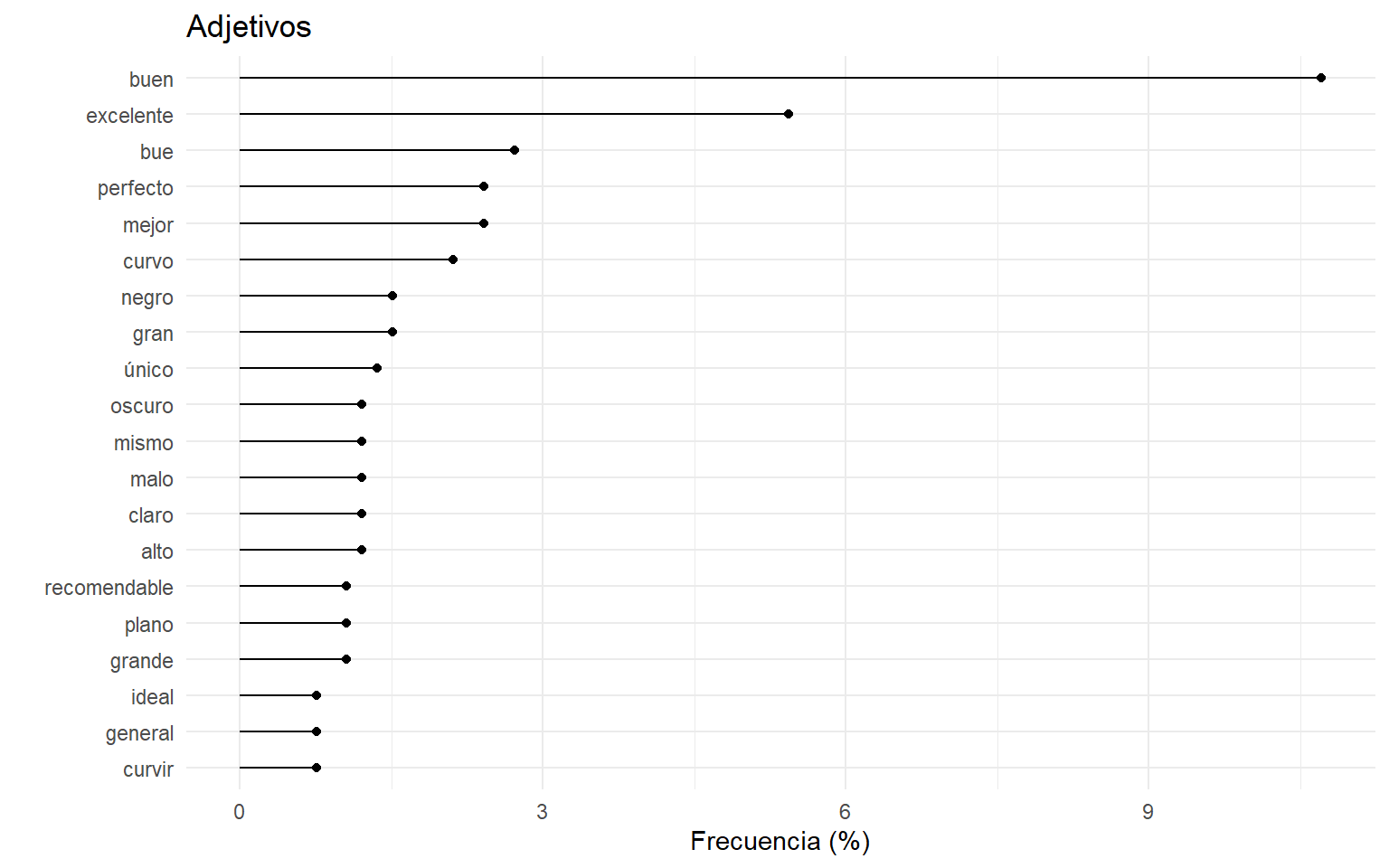
Que también podemos graficar como nube de palabras gracias {ggwordcloud}

O las palabras/frases clave:
rake_stats <- keywords_rake(x, term = "lemma", group = "doc_id", relevant = x$upos %in% c("NOUN", "ADJ"))
ggplot(head(rake_stats, 20), aes(reorder(keyword, rake), rake))+
geom_point()+
geom_linerange(aes(ymin = 0, ymax = rake))+
coord_flip()+
theme_minimal()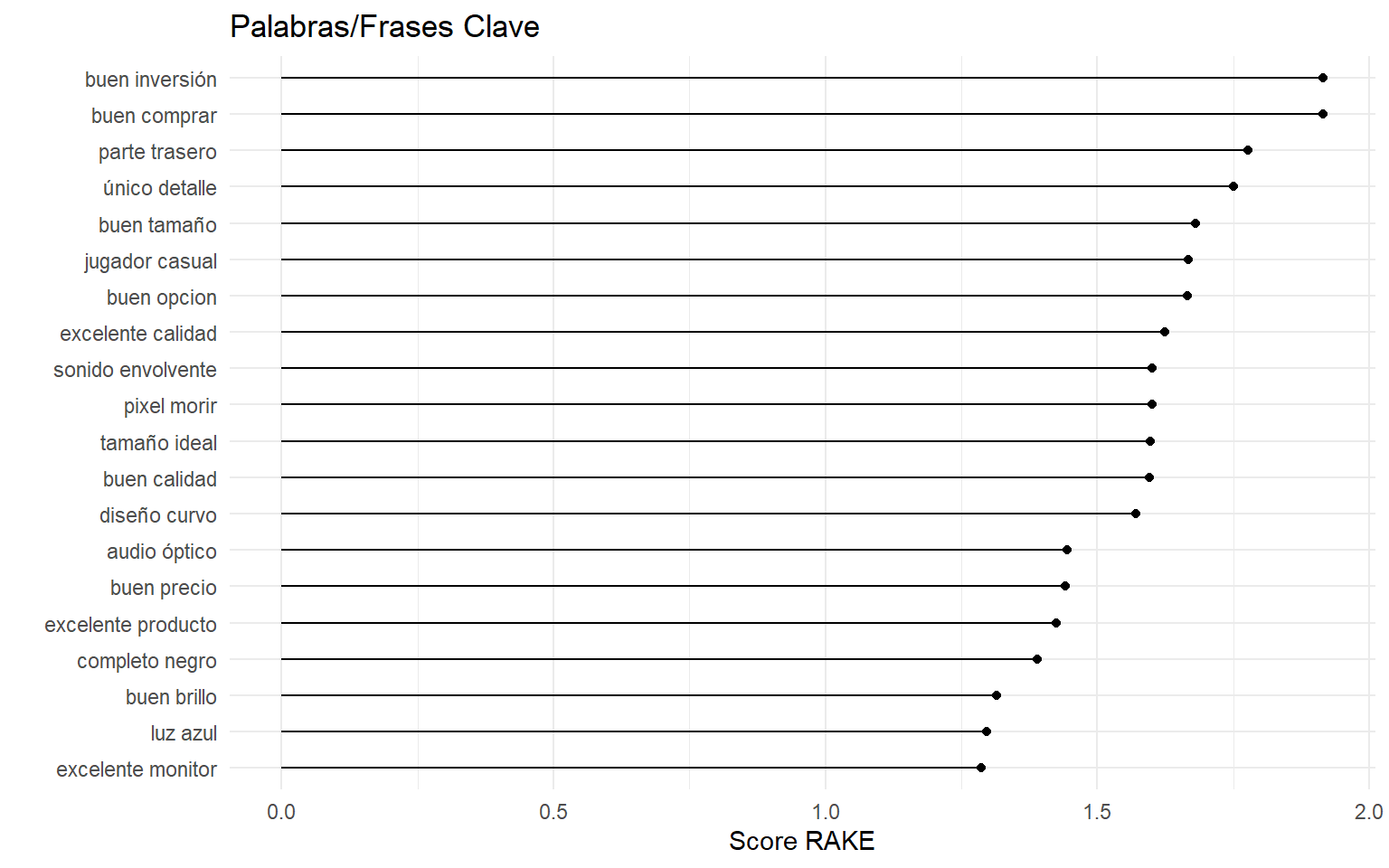

*Para las palabras/frases clave se utiliza un algorítmo de identificación llamado RAKE.
Reflexiones
La automatización creada para analizar los comentarios nos permite determinar que el producto en el que estamos interesados es evaluado como bueno y excelente.
Además podemos indentificar rápidamente que los temas más relevante en las opiniones son que el producto resultó una buena inversión, una buena compra y de buena calidad, por mencionar algunos.
Y no tuvimos que leer ninguno de los comentarios contenidos en 10 páginas 😎.
Por supuesto que el análisis puede ir más allá de lo que aquí mostramos, podríamos por ejemplo evaluar el sentimiento de los comentarios para fácilmente detectar si se habla de forma positiva o negativa del producto. También podrías extraer la cantidad de estrellas para tener un resumen visual rápido, etc.
Automatización completa
A pesar de que hemos logrado automatizar de buena manera el proceso de análisis de opiniones de Amazon aún tenemos que correr manualmente el código y si queremos compartir con alguien esta automatización, esa persona tendría que saber R.
Para no depender de tener que correr el código o estar limitado para compartirlo, he creado esta app que no solamente nos evitará la tarea de correr el código sino que además nos permitirá compartir estas herramientas con muchas más personas (y quiza pueda ayudarles a hacerles la vida más sencilla).
Únicamente hay que darle a la app la URL del producto en el que estamos interesados y listo. Incluso agregué una opción para cambiar el sitio entre Amazon México y Amazon US 😉.
Nota: La app está limitada a extraer 5 páginas de comentarios dado que el proceso es algo tardado si no quieres tener esa limitante lo mejor es instalar el paquete directamente en tu computadora.